Targeted Systems
The goal of the targeted systems subgroup is to develop common tools and infrastructure for the deployment of ML algorithms in a variety of dedicated science experiment systems, including those with stringent constraints on latency, resources, and throughput, and implemented in custom hardware, like FPGAs and ASICs. A variety of scientific applications are in development using these tools, including low-latency level-1 trigger algorithms (FPGA) and on-detector (ASIC) algorithms in HEP, signal reconstruction and prediction from brain electrocorticography (ECoG), anomaly detection, and multimodal denoising and feature detection in neuroscience, and front-end alert systems for gravitational wave detections in MMA. Members of the group develop open-source tools, including hls4ml, QONNX, PyLog, and HIDA.
Projects
hls4ml: high level synthesis for machine learning
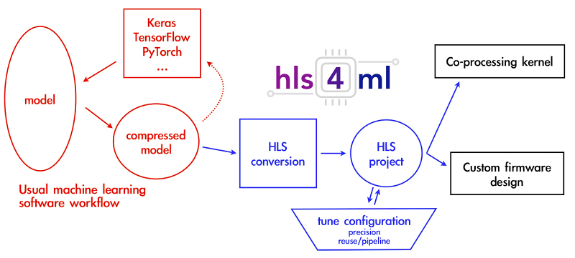
The hls4ml library is a user-friendly software package to automatically build and optimize Deep Learning models for FPGAs. It converts models trained with popular Deep Learning frameworks into FPGA firmware using HLS software. The library supports a broad array of frontends including Tensorflow, Keras, QKeras, PyTorch, ONNX, and back-ends like Vivado HLS, Vitis HLS, and is currently working on support for Intel HLS and Mentor Catapult.
A typical workflow using hls4ml to transition an ML model to FPGA or ASIC form is depicted in the adjacent figure. The process of model training and compression within traditional ML software frameworks is outlined in red boxes, while the configuration and conversion steps specific to hls4ml are highlighted in blue. Black boxes indicate the various methods for exporting and incorporating the HLS project into a larger hardware design scheme.
For more information, please see hls4ml.
QONNX: Arbitrary-Precision Quantized Neural Networks in ONNX
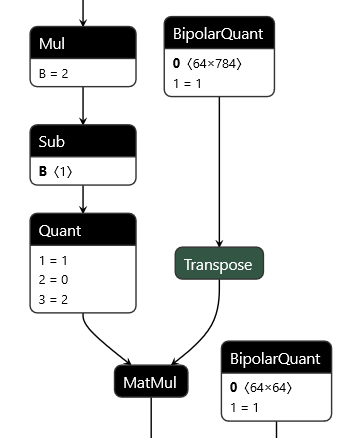
Tools such as hls4ml and Xilinx’s FINN serve as the integration layer between Deep Learning training libraries, referred to as the frontend, and the specialized processing required for deploying models on hardware, known as the backend. The frontend is where models are trained, often using frameworks like Keras or Pytorch, though it is increasingly common to employ quantization-aware training frameworks for this purpose. For example, hls4ml integrates with QKeras to facilitate this approach. In a collaborative effort involving Alessandro Pappalardo, the creator of Brevitas, and the hls4ml team, the QONNX (Quantized-ONNX) library was developed. QONNX, a variant of the standard ONNX format, introduces additional operators to enable flexible quantization while preserving compatibility with existing ONNX operators. This enhancement allows the FINN library to process models from QKeras and the hls4ml library to work with models developed using Brevitas.
The image on the left shows a model expressed in QONNX. It is standard ONNX with three additional node types (Quant, BipolarQuant,Trunc) that enable flexible expression of quantized networks.
For more information, please see QONNX.
PyLog: An Algorithm-Centric FPGA Programming and Synthesis Flow (shared with HAC)
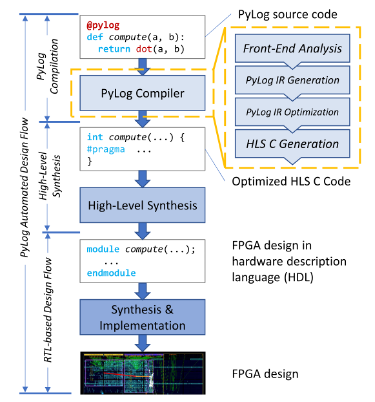
Similar to hls4ml, PyLog bridges the gap between high-level software development practices and hardware design by offering a Python-based programming and synthesis flow for FPGAs, streamlining the programming process and abstracting complex details. It automates the design flow by converting Python functions into an intermediate representation, performing optimizations, and generating FPGA system designs, all while allowing the code to run directly on FPGA platforms without additional development. This approach significantly simplifies FPGA programming, enabling developers to focus on algorithmic aspects rather than hardware intricacies.
For more information, please see here.
HIDA
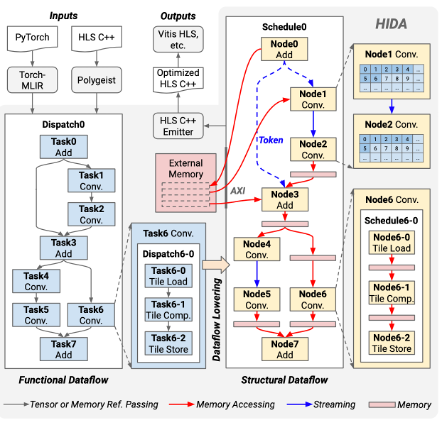
HIDA is a High-level Synthesis (HLS) framework built on the MLIR infrastructure, designed to compile HLS C/C++ or PyTorch models into optimized HLS C/C++ code, facilitating the creation of efficient RTL designs with tools like Xilinx Vivado HLS. Leveraging MLIR’s capability for fine-tuned optimizations across various levels of abstraction, ScaleHLS offers enhanced scalability and adaptability for diverse applications with unique structural or functional requirements. It operates across multiple abstraction levels, utilizing a dedicated library for analysis and transformation (available in C++ and Python) to address optimization challenges effectively. This framework includes a design space exploration engine that automates the generation of optimized HLS designs.
For more information, please see here.