Hardware and Algorithm Co-development
The Hardware and Algorithm Co-development (HAC) area is dedicated to pioneering novel AI algorithms and hardware support to serve various domain thrusts. Our mission is to craft AI algorithms capable of navigating the complexities of scientific data, addressing issues such as data irregularity, vast data volumes, limited labeling, and the need for robust model generalization during real-time experiments. Concurrently, we are committed to creating specialized hardware support tailored to these algorithms, aiming to meet specific computational demands including low latency, high throughput, and constraints on power and memory. A significant portion of our work involves developing tools for hardware design automation, enabling domain experts to more easily implement their AI algorithms on hardware.

One of the pressing challenges in contemporary AI systems is the development of methods to process non-lattice-structured data, a common feature in the scientific inquiries undertaken in A3D3. AI researchers must meticulously consider data irregularities, model architecture choices, and system limitations.
HAC is set to explore optimal encoders for handling these non-lattice-structured scientific datasets. Among the initiatives within A3D3’s science drivers, the rapid detection of sporadic events in large-scale data streams presents a promising avenue for discovery. Traditional selection methodologies often rely on subjective heuristics (such as the occurrence of a high-energy collision or a bright transient) or model-based classifiers trained on specific labels, neglecting unconventional signatures that don’t fit predefined heuristics or labeled examples.
To address these limitations, HAC intends to investigate the use of decoders trained on encoded data, e.g., employing semi-supervised or unsupervised learning techniques for efficient anomaly detection or identification of out-of-class events. Recent advancements in variational autoencoders (VAEs) and generative models, which learn the distribution of input data and identify anomalies through likelihood scores, underscore the potential of these approaches. The essence of hardware-AI co-design lies in the seamless integration of AI algorithm development with domain science, hardware specifications, and system constraints. This approach is characterized by incorporating design constraints directly into the cost function of the training algorithm or by devising a rapid evaluation method to assess the feasibility of solutions on devices, facilitating swift exploration and assessment.
Our primary objective is to enable low-latency, real-time processing of scientific data. A3D3 is dedicated to creating comprehensive workflows, complemented by user-friendly tools, for the hardware-aware co-design of AI algorithms, ensuring efficient and effective processing of scientific inquiries.
Project Highlights
1. Algorithm-System-Hardware Co-development for Point Cloud Data Processing
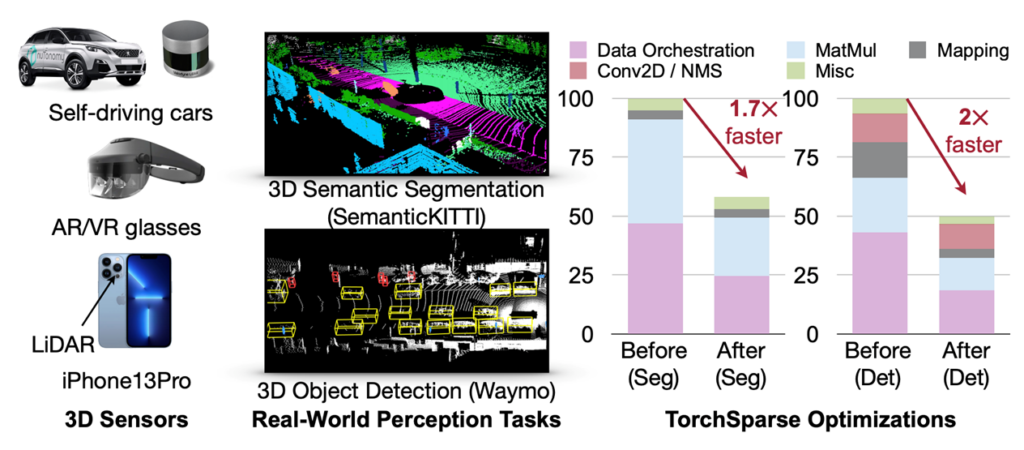
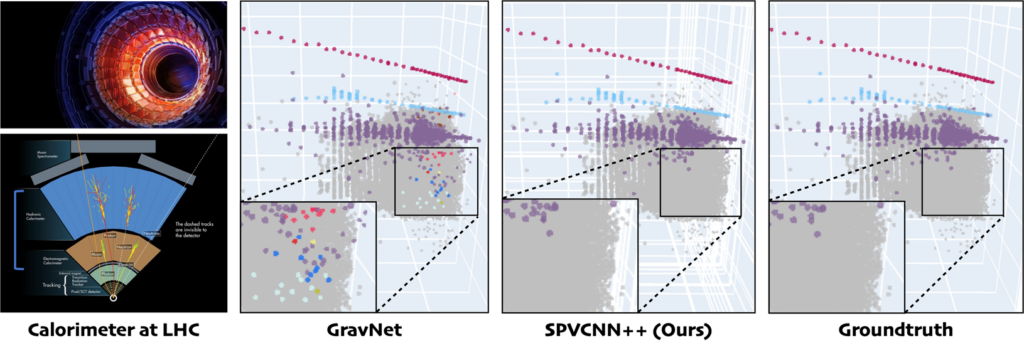
The generic algorithm and hardware support is available for all scientific domains to use. HAC and HEP teams are working on specializing and applying the sparse CNN model based on torchsparse to the Hadron Calorimeter (HCAL) and the High Granularity Calorimeter (HGCAL). A novel dedicated loss function and a new voxel-to-point transform for per-particle prediction has been developed for this application. We have achieved 4% higher mIoU and 10+% higher PQ than GravNet (a GNN-based baseline).
Point cloud computation has become an increasingly more important workload for autonomous driving and other applications. Unlike dense 2D computation, point cloud convolution has sparse and irregular computation patterns and thus requires dedicated inference system support with specialized high-performance kernels. While existing point cloud deep learning libraries have developed different dataflows for convolution on point clouds, they assume a single dataflow throughout the execution of the entire model. This project led by MIT is to co-design algorithms and hardware to substantially accelerate 3D point cloud convolution. The resulting system, TorchSparse++, achieves 2.9x, 3.3x, 2.2x and 1.7x measured end-to-end speedup on an NVIDIA A100 GPU over the state-of-the-art MinkowskiEngine, SpConv 1.2, TorchSparse and SpConv v2 in inference respectively.
The generic algorithm and hardware support is available for all scientific domains to use. HAC and HEP teams are working on specializing and applying the sparse CNN model based on TorchSparse to the Hadron Calorimeter (HCAL) and the High Granularity Calorimeter (HGCAL). A novel dedicated loss function and a new voxel-to-point transform for per-particle prediction has been developed for this application. We have achieved 4% higher mIoU and 10+% higher PQ than GravNet (a GNN-based baseline). More details can be checked here.
2. Interpretable and Distributionally Robust Graph/Point Cloud Learning Models
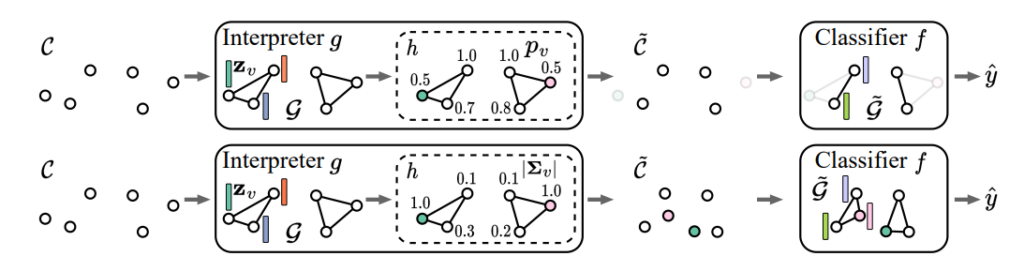
The objective of this project is to develop deep learning models that are both interpretable and generalizable, specifically designed to process graph-structured or point cloud data. These advanced models are aimed at scientific applications, enabling domain experts to gain insights into the model’s predictions and to trust its reliability, even when there are minor discrepancies between the training data and real-world experimental conditions.
To achieve this, we have introduced a cutting-edge, inherently interpretable architecture known as “graph stochastic attention,” designed specifically for interpreting graph neural networks. This framework has been expanded into the realm of geometric deep learning, empowering the model to not only pinpoint critical point patterns within point clouds but also to detect sensitive geometric features. Additionally, we have devised two innovative algorithms, StruRW and Pair-Align, to tackle the challenges posed by the irregular distributions characteristic of graphs and point cloud data, ensuring their applicability and performance in real-world experimental settings.
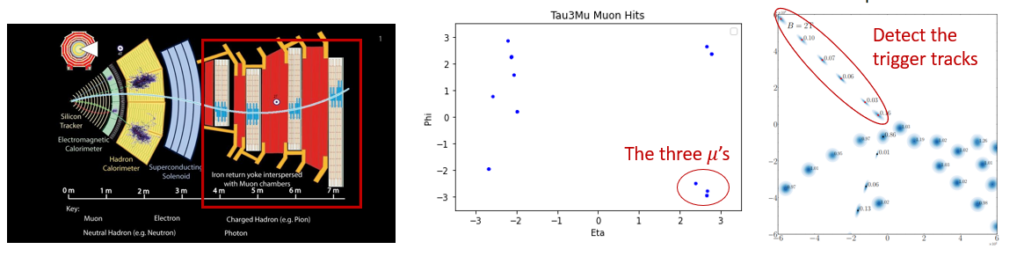
As of now, we have made available a versatile algorithm along with the necessary hardware support, marking a significant step forward in our project’s development. The method is now under development for the application tasks in high energy physics such as pileup mitigation, Tau3Mu detection, etc. More details can be checked via these links: GSAT and StruRW.
3. PyLog: An Algorithm-Centric Python-Based FPGA Programming and Synthesis Flow
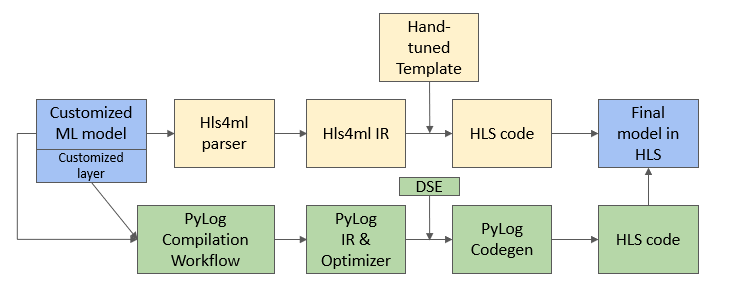
A significant recent advancement in this project is the effort to integrate PyLog with HLS4ML, marking a collaborative initiative between the HAC and targeted system teams. HLS4ML traditionally relies on hand-tuned templates to convert Python operations into High-Level Synthesis (HLS) code. Through our integration with PyLog, we aim to extend HLS4ML support to more general Python libraries, enabling automatic transformation into HLS code. This integration promises to broaden the applicability and efficiency of FPGA programming in machine learning applications, paving the way for more accessible and powerful computational tools in scientific research.
This project represents a collaborative endeavor between the HAC team and the targeted systems team, aiming to enhance the programmability of FPGA systems through the development of a Python-level abstraction for FPGA programming. We have successfully developed and demonstrated the efficacy of this approach with applications such as Canny Edge Detection, showcasing the FPGA implementation’s superior performance—achieving speeds 50 to 300 times faster than its CPU counterpart—utilizing PyLog. Further, we have integrated backend support for PyLog with the Merlin Compiler and are currently exploring the use of ScaleHLS as an alternative backend. More details can be checked here.