A3D3 Accelerates Real-Time AI for Scientific Discovery at FastML 2025
By: Abdelrahman Elabd
September 18, 2025
Zurich, Switzerland -The cutting edge of computing and instrumentation has enabled fields like high-energy physics (HEP), multi-messenger astronomy (MMA), and even materials science to generate increasingly complex, high-resolution and high-frequency datasets – projecting reality onto a more expressive and higher-dimensional representation than ever before. Our finite storage capacity, bandwidth, and response time calls for hardware-accelerated machine learning (ML) inference to enable real-time processing and control of this new generation of science experiments. The 2025 Fast Machine Learning for Science conference, held at ETH Zurich from September 1-5, spotlighted groundbreaking advancements in both the development and application of these “FastML for Science” algorithms. A3D3 scientists and engineers discussed fundamental engineering efforts to develop faster science workflows, as well as domain-specific applications of these accelerated workflows – contributing a total of 11 talks and 6 posters, one of which received a best poster award.

Contributed Talks

Among the distinguished contributors was Yuan-Tang Chou, who presented the highly impactful SuperSONIC framework—an infrastructure for scalable deployment of ML inferencing on Kubernetes clusters with GPUs. This platform optimizes resource utilization in experiments at CERN’s Large Hadron Collider and other scientific observatories. [paper link, project link]
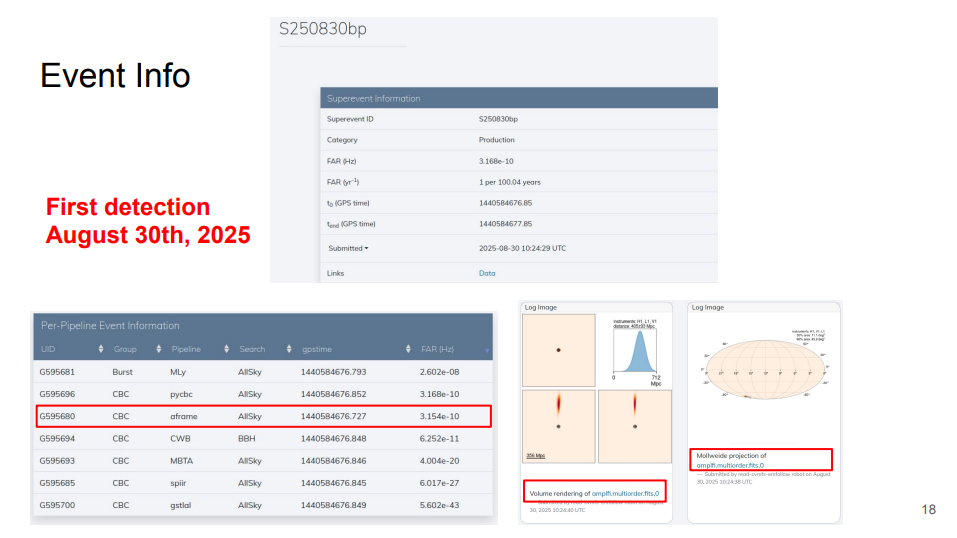
Christina Reissel presented an ML pipeline for real-time gravitational wave alerts, reacting to early-messenger astronomy signals by directing other observatories and experiments across the globe to turn their telescopes and antenna toward incoming, often short-lived signals. She also announced the recent first detection enabled by this pipeline – a gravitational-wave signal from a likely neutron star merger! This work showcases how low-latency ML allows MMA researchers to collect more and better data by enabling faster response times. [project link]

Bo-Cheng Lai reported on a hierarchical dataflow accelerator for large-scale particle tracking on FPGAs at the LHC, demonstrating orders of magnitude speedup over CPU, GPU, and less-optimized FPGA baselines. This work emphasized the importance of high-level optimization and engineering for hardware-accelerated algorithms – it’s more than just choosing a specific hardware accelerator!

Abdelrahman Elabd introduced an FPGA algorithm for a novel science application of FastML – real-time in-situ characterization of materials being grown via thin-film deposition. This algorithm achieves sufficient latency and throughput to enable real-time monitoring and control of dynamic, non-equilibrium growth processes such as pulsed-laser deposition. This work is an example of R&D by HEP and MMA researchers bleeding into and benefiting other fields of science!
Katya Govorkova presented an ML-based compression algorithm that also denoises and extracts timing-information from photomultiplier tube pulses at the LHCb detector. The algorithm satisfies both the latency constraints and the resource-usage constraints of the radiation-hard PolarFire FPGAs on the detector – making this a promising approach for Upgrade II of LHCb, after which a huge 200 Tb/s data rate is expected during the future High-Luminosity phase of the LHC.

Olivia Weng discussed PrioriFi, an efficient fault injection framework to inspect and estimate bit-flip-sensitivity of edge-AI algorithms, allowing one to tune and optimize the efficiency-robustness tradeoff. PrioriFI enables designers to quickly evaluate different NN architectures and co-design fault-tolerant edge NNs.
Kenny Jia discussed how the Generic Event-Level Anomalous Trigger Option (GELATO) can improve sensitivity to new physics at the ATLAS experiment. This work highlights how data volumes at the Large Hadron Collider (LHC) allow for unsupervised machine learning to significantly enhance the trigger system.
Duc Hoang unveiled a look-up-table (LUT) based compression workflow for Kolmogorov-Arnold Networks (KANs) on FPGAs, offering significant improvements in hardware efficiency for ultra-low latency inference.
Eric Moreno introduced the COLLIDE-2V dataset, a huge dataset of 750 million simulated collision events, providing a universal event representation and enabling development across the entire LHC data stack – from training collider foundation models, to developing anomaly-detection triggers, among many other things. This work is a crucial step in the right direction for consolidating the wide variety of LHC data workflows. [Huggingface link]
Jan-Frederik Schulte discussed an accelerated transformer architecture tailored for particle-tracking on FPGAs based on point-cloud input data. The model achieves microsecond latency on AMD/Xilinx FPGAs by leveraging hls4ml technology and model compression strategies such as pruning and quantization-aware training (QAT).
Ho-Fung Tsoi introduced SparsePixels, a framework for training and deploying efficient convolutional neural networks (CNNs) for sparse data on FPGAs. SparsePixels implements a special class of CNNs that dynamically select and compute only on active pixels (non-zero or above a threshold). It demonstrated accuracy comparable to standard CNNs while achieving orders of magnitude lower latency on FPGAs for datasets with fewer than ~5% active pixels.
Posters
Erdem Yigit Ertorer also discussed data compression at the High-Luminosity LHC (HL-LHC), introducing an autoencoder-based compression algorithm for high-granularity calorimeter data.
Jared Burleson and Hao-Chun Liang discussed two more innovative approaches for high-throughput particle-tracking at the high-level trigger (HLT) of the HL-LHC: graph neural networks (GNNs) on FPGAs and Kalman-Filters on GPUs, respectively.
Yuan-Tang Chou and Christina Reissel each presented once more, on efficient point-transformers for charged-particle reconstruction and state-space models for time-series applications, respectively, with Yuan-Tang’s poster winning 2nd place in the best poster award!
Takeaway
The FastML conference at ETH Zurich underscores the ever accelerating fusion of AI, state-of-the-art electronics, and experimental science. As we head toward a future where science experiments produce exponentially more data at exponentially faster speeds, only with the right research and development can we translate that vast data into deep insights that illuminate the dark secrets of our universe. A3D3 stands as a central institution in this push toward the future.
For additional details, each speaker’s contributions and talks are catalogued in the conference’s event site.